tensorpack——Dorefa-alexnet(二)
上次跑通的是Dorefa样例下的svhn-digit-dorefa.py代码,这次准备跑alexnet-dorefa.py,其中碰到了无数的bug,折腾了好几天,终于跑通了!这里只挑选其中几个我花时间最多的bug。
一、数据集路径
虽然官方代码有描述数据集路径,但对于脑残的我,还是不太理解,还是上图吧:
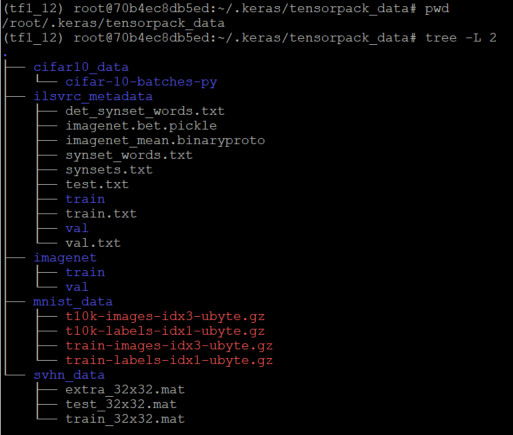
代码默认的目录是~/tensorpack_data/数据集,跑alexnet-dorefa.py的--data路径就是:/root/.keras/tensorpack_data/imagenet/
二、cuda环境错误
按如下代码运行:
python alexnet-dorefa.py --data /root/.keras/tensorpack_data/imagenet/ --dorefa 1,2,6 --gpu 0,1
出现Registered devices: [CPU, XLA_CPU, XLA_GPU]错误,感觉和硬件有关,参考这篇文章,说单GPU训练的时候是可以的,多GPU训练会碰到,于是为了先跑通,将--gpu 0,1改为--gpu 0。结果确实通过了,然后有了新的错误:
Default MaxPoolingOp only supports NHWC on device type CPU
搜了好久,才在tensorpack的论坛上找到原因,原来确实是GPU的问题,可以通过如下代码验证:
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
结果确实发现少了库,报错是确实动态库:
libcublas.so.10.0: cannot open shared object file: No such file or directory
原来我的tensorflow是1.14.0版本,需要cuda10.0版本,对应的cudnn7.4.2版本。一开始还想上官网装cuda,又会是繁琐的工程,没想到可以借助conda快速配置环境:
conda install cudatoolkit=10.0
conda install cudnn=7.4
三、总结
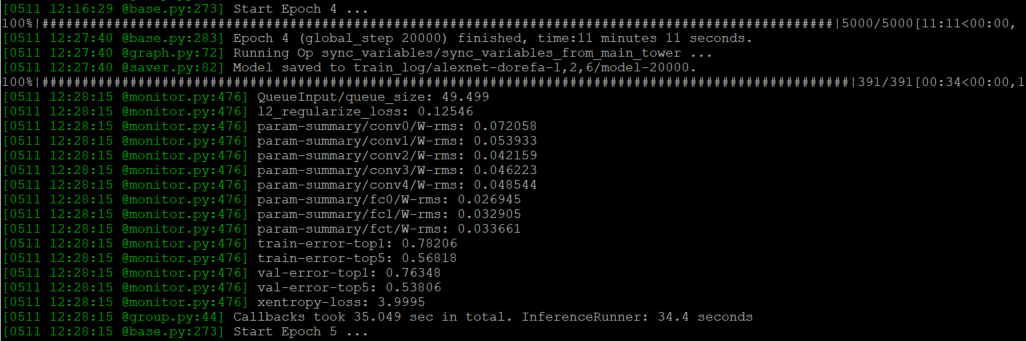
神经网络快把我变神经病了,配置环境花了那么多时间!看似简简单单的几条命令,背后却是满满的辛酸泪。。。 python,tensorflow,cuda,cudnn版本官方对照 这下终于可以运行了:
python alexnet-dorefa.py --data /root/.keras/tensorpack_data/imagenet/ --dorefa 1,2,6 --gpu 0,1
nvidia-smi -L #可以查看可以调用GPU的编号
上图纪念一番: